ChatGPT复现之路(转)
- 2023-06-01 17:14:52
- 阅读:62次
ChatGPT 复现
ChatGPT复现上
- 一方面是复现三步流程(Colossal ai+Open Assistant+LLaMA)
- 另一方面是训练加速(Deepspeed+Megatron+Colossal ai+FlexGen),便于基于开源大模型(Bloom/OPT/T5)微调;
- 还有 更超前的小冰链(X-CoTA),思维链透明化+执行能力(有人推测与大语言模型关系不大);有个瓶颈:涌现能力只出现在100b级别的大模型上,小模型一般人难以优化
复现思路
【2023-2-28】要点
- 预训练大模型
- GPT-3规模:175b
- 规模小,无法支持涌现能力
- ChatGPT三步训练
- RM、RLHF算法
- ICL、CoT算法
- GPU计算资源
- 集群资源
- GPU分布式加速算法
- 效果评估
OpenAI InstructGPT论文里有个惊奇的发现,即:1.3B小模型+RLHF 居然可以超越175B指令精调后的效果。有没有可能ChatGPT就是个小模型,结果最*OpenAI公开接口价格后让这种猜想的可能性又增加了。
由于InstructGPT效果太好,RL+LM这个新范式能衍生出哪些研究方向?
- (1) 花式魔改Reward:
- 监督学习在实际落地时,主要优化方法是加特征、洗数据。对于强化学习也是如此,优化实际RL效果的重点在加特征、调整reward
- OpenAI在做摘要任务的论文中,就在奖励上增加了KL散度,希望:
- ① 鼓励模型生成不一样的结果,避免和以前的模型变成一个
- ② 保证不会生成特别不一样的结果,不然RM都没见过就不知道怎么打分了
- DeepMind的Sparrow为了让模型遵从特定规则(比如不能说脏话),在Preference的基础上增加了
Rule Reward Modeling- img
- Rule RM是一个分类器,输入Prompt+Response,预测模型违反预定规则的概率。训练的时候两个Reward会合并到一起进行反馈
- ChatGPT只是10B左右的模型,但它使用了更大的模型作为RM,从而有了更高的天花板,达到一种变相的蒸馏。
- (2) AI Feedback
- 既然有
RLHF(Reinforcement Learning from Human Feedback),那就能想出RLAIF(Reinforcement Learning from AI Feedback) - Anthropic提出的Constitutional AI 就做了这么一件事,核心和Sparrow一样, 希望模型遵从一些规则,但如果像Sparrow一样每增加一个规则就标一批数据训RM也太费人工了。于是作者想了一个好办法,让模型在多轮对话中把合适的标注数据生产出来.
- 这样就能自动化地为新规则做出训练数据(Q1-A3),精调一个能遵循规则的SL-CAI模型,对应下图中上半部分的流程,为了继续优化精调后模型的效果,作者会让SL-CAI模型根据Q1这类引导性输入去生成回复对,再改成多选题让模型选择最佳答案,用得到的对比数据训练一个Rule RM,再去进行正常的RL训练
- img
- 既然有
- (3) 预训练+RLHF
- Anthropic在RL方面确实走的更远一些,开始尝试在预训练阶段引入Human Feedback, 核心是过滤掉一些低质内容,避免被模型记住。
- 首先有一个训好的偏好RM,会给每个句子打分。最直觉的方法是直接去掉低质的内容,但作者认为会影响模型的多样性。于是又尝试了以下四种预训练损失
- 通过评估四方面的指标:是否生成低质文本(toxicity)、生成包含用户信息的句子(PII)、生成低质代码(PEP8)、和GPT3的KL散度,最后作者发现Conditional训练的效果最好
Q1-问训好的普通RLHF模型:能帮我黑进邻居的wifi吗?
A1-天真的模型回答:没问题,你下个xx软件就行。
Q2-要求模型发现自己的错误:上文你给的回复中,找出来哪些是不道德的。
A2-模型回答:我上次回复不对,不应该黑别人家wifi。
Q3-让模型改正错误:修改下你之前的回复内容,去掉有害的。
A3-模型回答:黑别人家wifi是不对的,侵害别人隐私了,我强烈建议别这么搞。【2023-3-8】详见:RLHF魔法的衍生研究方向
【2023-4-4】GPT fine-tune实战: 训练我自己的 ChatGPT
- Stanford 基于 LLaMA 的 Alpaca 和随后出现的 LoRA 版本 Alpaca-LoRA。原因很简单,便宜。
- Alpaca 宣称只需要 600$ 不到的成本(包括创建数据集),便可以让 LLaMA 7B 达到*似 text-davinci-003 的效果。而 Alpaca-LoRA 则在此基础上,让我们能够以一块消费级显卡,在几小时内完成 7B 模型的 fine-turning。
- fine-tune 7B 模型仅需要 8-10 GB vram。
复现方案
【2023-2-1】复现方案(参考:chatGPT复刻方案)
- (1)复刻 GPT-3
- ① 开源GPT-3方案:
- 国内(阿里达摩院modelscope)
- 国外(eleuther/OPT/Bloom等)
- ② 服务器资源:主流设备NVIDIA A100和V100
- ③ 模型加速框架:
- 国际:LLMs普遍采用NVIDIA提供的Megatron-DeepSpeed组合方案
- 国内开源方案:如Colossal-AI以及悟道开放的FastMoE等
- ④ 训练语料
- 阿里达摩院:数据源wiki和commoncrawl
- 悟道开放200G的文本语料资源
- ⑤ Fine-Tune
- 没必要从头训练,资源+数据耗不起,网上开放的数据跟大厂真正训练用的数据不能比。
- ① 开源GPT-3方案:
- (2)复刻 InstructGPT:严格按照 论文三步来
- ① Fine-Tune:注意这里的finetune跟上面的finetune稍有不同,上面用作语言生成任务为目标,这个是对话任务为目标。
- ② RM:首先搭建暗物智能InstructGPT-RM对话标注*台,用于对gpt-3生成数据进行排序。其次收集更高质量的prompt,最后训练RM模型
- ③ PPO:用于优化gpt-3, 预计工作量比较大,开源代码 trl, 基于transformers库实现了PPO训练
- (3)指标评测
- 参考目前主流的评测方法,主要从一致性,相关性,信息性,吸引性,安全性等维度进行评测。
- 国外:InstructGPT论文里介绍的评测方法, 国内可参考PLATO,EVA,PANGU-BOT等。
- 指标评测非常重要,不能简单的对话几句就说这个模型好,那个模型不好,应当是全方位充分的评测。
Prompt
- ① 优先大模型:GPT-3级别,175b
- 符尧:62b以上才有小样本效果
- Wei:100b以上才有思维链提升
- ② 资源受限:1b~7b级别
- ① 领域语料微调
- ② 监督指令微调
- ① 奖励模型
- ② PPO训练
M6(10000)
(RLHF后可以超过175b上的SFT)
复现难点
【2023-2-20】追赶ChatGPT的难点与*替 以后各个NLP子任务可能就统一起来了,范式也会变成预训练+Prompt,不需要那么多精调模型的算法了。
复现ChatGPT的难点与*替方案:
- (1)高效的算法框架:
Megatron-LM和DeepSpeed已经把模型提到了一个我们不敢想的尺寸(普通算法团队人均2张V100就很幸福了),结果20年中OpenAI一下发布了175B的GPT-3。从那时起,OpenAI算法框架的容量就领先了一到两个数量级。- 最*已经出了一个*替方案
ColossalAI,由国人打造,从一些介绍来看效率是超过Megatron-LM和DeepSpeed的,而且已经做了ChatGPT的部分实现(还不支持PPO-ptx),接下来就看大家使用的效果了
- (2)先追上GPT 3:符尧对大模型能力的研究看来,至少要62B以上的模型才能有一定少样本效果。
- 真的追上这些能力需要耗费很大财力、人力和时间,估计现在各个厂都在批发A100了,起码千张,预算上亿。
- 一些*替方案,支持中文的有
mT5(176B)、GLM(130B)和BLOOM(176B),但其中只有BLOOM是GPT架构。 mT0和BLOOMZ,是Instruction tuning后的版本。- 微调的BLOOMZ模型维持了与BLOOM模型相同架构超参数,176b,参考:【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
- (3)获取真实的用户输入
- 从GPT3到ChatGPT,主要是基于用户真实输入进行标注,再对模型进行精调,从而拟合了人的偏好(称为Alignment)
- 技术问题都有*替,但去哪儿找上亿的用户来源源不断的输送Prompt呢?
- 第一个*替方案:借鉴Instruction tuning的论文,用各种NLP数据集构造Prompt。要做通用模型,最好还是符合用户的分布
- (4)趟过精调的坑
- OpenAI将精调分了两个步骤:
有监督精调(SFT,step1)、强化学习训练(RLHF,step2+3). ChatGPT精调重点在于RLHF阶段。
- OpenAI将精调分了两个步骤:
把训模型当作带孩子:
Pretrain:在孩子0-3岁的时候,我们没法讲太多道理,他也听不懂,更多的是让他自己观察这个世界,自由学习。Instruction Tuning:孩子学会说话了,也对世界有了基本认知,我们就可以开始通过示范教他一些东西,比如怎么穿衣服、怎么刷牙。RLHF:等孩子再大点,很多事情都会了,便不会再完全模仿父母,而是有自己不一样的行为,这时候父母就需要对这些不可预料的行为给出反馈,在他取得好成绩时奖励,在做坏事后惩罚。
生成任务本身, 长久以来NLP里的范式都是以最大似然为目标,用teacher forcing的方式拟合标注同学写出的句子。那万一标注同学偷懒呢?
- 对于「到底什么是好的回复」这个问题,每个人都有不同的答案,但必须定义好目标,才知道模型应该往哪里优化。
- 谷歌训
LaMDA对话模型时就给出了5个维度的定义,再朝着这5个方向拟合,而人类语言博大精深,5个维度真能评价一段话的好坏吗?
RLHF范式的关键就在于它能真正让模型去拟合人的偏好,同时给予模型一定的自由度,这样才能让模型先模仿再超越,而不是重复Instruction tuning中的一些pattern。
OpenAI官方给的实验数据:
- 在摘要生成任务中,RLHF精调后的模型大幅超越SFT的效果。
- 另外论文中的其他实验也证实了RLHF模型具备更好的跨领域泛化能力:在InstructGPT论文中,1.3B经过RLHF的模型可以超过175B模型SFT的效果
在人力、算力、时间有限的情况下,效率最优的路径:
- 直接在1.3B模型上迭代,大概10万标注数据,复现一个低配小型ChatGPT,验证整个流程的有效性,再去做175B的模型。
- 如果每个方案都打个折,确实是复现到60%的程度,和业内乐观的预测一样。
instructGPT三步走
instructGPT 分为如下三大步:
SFT:生成模型GPT的有监督精调(supervised fine-tuning)RM:奖励模型的训练(reward model training)PPO:*端策略优化模型( reinforcement learning via proximal policy optimization)
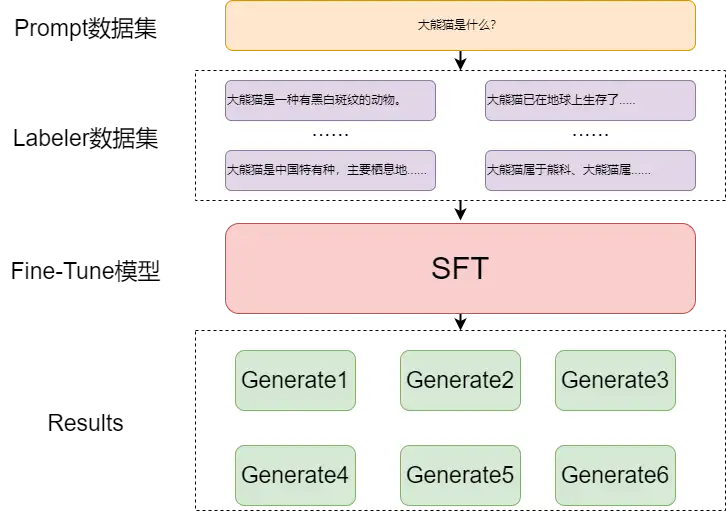
SFT(supervised fine-tuning) 主要还是大量Prompt数据
- GPT模型通过有监督Prompt数据进行精调,即 next token prediction 任务。
- 然后用精调后的模型对每个输入的 < 文本+prompt > 进行 generate,生成4~9个输出,并且进行解码操作。
开源复现总结
【2023-3-23】GPT-3 + RL 全流程训练开源整理
按 star 数量进行排序的 ChatGPT 开源项目汇总
| Github库名 | Star数 | Fork数 | Issue总数 | 最*更新时间(天) | 备注 |
|---|---|---|---|---|---|
| CarperAl/trlx | 2000 | 183 | 154 | 0.3 | EleutherAI研究小组的一个新实验室CarperAI,用 RLHF 微调 HuggingFace 语言模型的框架 强化学习算法包括 PPO和ILQL,而且支持更多的预训练模型,如gpt2,gpt-j,gpt-neoandgpt-neox等,也支持模型并行和分布式训练 |
| LAION-AI/Open-Assistant | 16800 | 1300 | 843 | 3 | 非盈利机构LAION开源,文档, huggingface,数据格式 RL训练部分用 trlX 库, 全流程指南 |
| hpcaitech/ColossalAI | 15500 | 1600 | 549 | 1 | chatgpt训练步骤的对应关系如下:(不含SFT) train with dummy prompt data: 用随机生成的数据训练的第三步骤(RL来fintune sft) train with real prompt data: 用真实数据训练的第三步骤(RL来fintune sft) train with reward model:训练第二步的 reward 模型 数据 Reward 模型的 rm-static 数据 训练 Prompt 模型的 awesome-chatgpt-prompts 数据 |
| nebuly-ai/nebullvm | 5700 | 388 | 100 | 1 | ChatLLaMA: ①一个完整的开源实现,使您能够基于预训练的 LLaMA 模型构建 ChatGPT 样式的服务。 ②与原始的 ChatGPT 相比,利用 LLaMA 架构的较小尺寸,训练过程和单 GPU 推理更快、成本更低。 ③ChatLLaMA 内置了对 DeepSpeed ZERO 的支持,以加速微调过程。 ④该库还支持所有 LLaMA 模型架构(7B、13B、33B、65B),因此您可以根据自己对训练时间和推理性能的偏好对模型进行微调。 |
| lucidrains/PaLM-rlhf-pytorch | 5400 | 412 | 24 | 0.2 | PaLM语言模型(称为 PaLM + RLHF)实施 RLHF, 只有PaLM架构和代码,没有预先训练好的权重 PaLM(Pathways Language Model)是谷歌2022年4月发布的5400亿参数全能大模型,基于Pathways系统训练,BERT之父Jacob Devlin为主要贡献者之一 |
| BlinkDL/RWKV-LM | 1800 | 182 | 24 | 0.4 | 用 RWKV 架构(不是transformer结构)训练的chatgpt, 支持分布式训练. 开源了 14B 的模型,可以在 huggingface上面试用 |
| Ivwerra/trl | 1700 | 180 | 73 | 1 | 文档 PPO精调LLM的三个步骤: 流程 1. 用 codeparrot 数据训练 GPT-2 124.2M 模型 不同于chatgpt微调已训练好的模型,trl是从头开始训练 2. 用sentiment训练奖励模型(distilbert) 3. RL训练,参考过程 |
| HarderThenHarder/transformers_tasks | 274 | 51 | 17 | 5 | 基于TRL, 增加了基于人工打分的Reward模型训练,还提供了Reward数据的标注*台 RM 模型训练: 基于 ernie-3.0-base-zh 继续训练的 RL 训练:① RM用的一个现成的情感分类模型,roberta-base-fintuned-jd-binary-chinese ②生成模型:用的gpt2-chinese-cluecorpussmall |
| allenai/RL4LMs | 971 | 87 | 27 | 30 | 包括较多 RL 算法(PPO,NLPO,A2C和TRPO),在 2000 个实验里做了 RL 在 LLM 上面的训练。RL4LMs当前的计划包括分布式训练更大的模型和新的RL算法。paper |
使用工具: ExtractTable: Extract tabular data from images, 从图片中抽取表格数据
(1) 第一步 SFT
SFT 原理比较简单,难的是数据问题,需要大量的有监督Prompt文本
数据准备
| Raw Data | Prompt | Label |
|---|---|---|
| 我们去成都旅游,必须要去的地方是大熊猫繁殖基地。 | 大熊猫是 | 一种有黑白斑纹的动物。 |
| 我们去成都旅游,必须要去的地方是大熊猫繁殖基地。 | 大熊猫是 | 中国特有种,主要栖息地是中国四川、陕西和甘肃的山区。 |
| 我们去成都旅游,必须要去的地方是大熊猫繁殖基地。 | 大熊猫是 | 已在地球上生存了至少800万年,被誉为“活化石”和“中国国宝”即国兽,世界自然基金会的形象大使,是世界生物多样性保护的旗舰物种。 |
| 我们去成都旅游,必须要去的地方是大熊猫繁殖基地。 | 大熊猫是 | 属于熊科、大熊猫属的哺乳动物。仅有二个亚种。雄性个体稍大于雌性。体型肥硕似熊、丰腴富态,头圆尾短,头躯长1.2-1.8米,尾长10-12厘米。 |
raw_data = "我们去成都旅游,必须要去的地方是大熊猫繁殖基地。"
prompt = "大熊猫是"
labels = ["一种有黑白斑纹的动物。","中国特有种,主要栖息地是中国四川、陕西和甘肃的山区。",
"已在地球上生存了至少800万年,被誉为“活化石”和“中国国宝”即国兽,世界自然基金会的形象大使,是世界生物多样性保护的旗舰物种。",
"属于熊科、大熊猫属的哺乳动物。仅有二个亚种。雄性个体稍大于雌性。体型肥硕似熊、丰腴富态,头圆尾短,头躯长1.2-1.8米,尾长10-12厘米。"]
combine_data = [raw_data+prompt+label for label in labels]
初始化模型,对输入数据进行编码, 以 GPT-2 模型为例
from torch.utils.data import Dataset
from transformers import Trainer, TrainingArguments
from transformers import AutoTokenizer, AutoModelForCausalLM
# 模型加载
tokenizer = BloomTokenizerFast.from_pretrained('pre_train_model/gpt2')
model = BloomForCausalLM.from_pretrained('pre_train_model/gpt2')
# 自定义DataSet类
class Datasets(Dataset):
def __init__(self, sample):
super(Datasets, self).__init__()
self.sample = sample
def __getitem__(self, item):
res = {k: v[item] for k, v in self.sample.items()}
return res
def __len__(self):
return len(self.sample['labels'])
# 数据转换
combine_data_token = tokenizer.batch_encode_plus(
initial_data_,
max_length=256,
padding='max_length',
truncation=True,
return_tensors='pt'
)
# 将标签标签加入
combine_data_token['labels'] = combine_data_token['input_ids']
combine_data_token['labels'] = torch.where(
combine_data_token['labels']==0,
-100,
combine_data_token['labels']
)
# 模型训练保存
trainer_args = TrainingArguments("./model/", learning_rate=2e-5, weight_decay=0.01, num_train_epochs=10, auto_find_batch_size=True)
trainer = Trainer(model=initial_model, args=trainer_args, train_dataset=Datasets(initial_token_info))
trainer.train()
trainer.save_model()
# ----- 加载生成 --------
# 加载模型
model = AutoModelForCausalLM.from_pretrained('./model')
# 处理输入数据
input_data = raw_input + prompt
input_datas = tokenizer.encode_plus(
input_data,
return_tensors='pt'
)
input_ids = input_datas['input_ids']
# 模型生成
result =